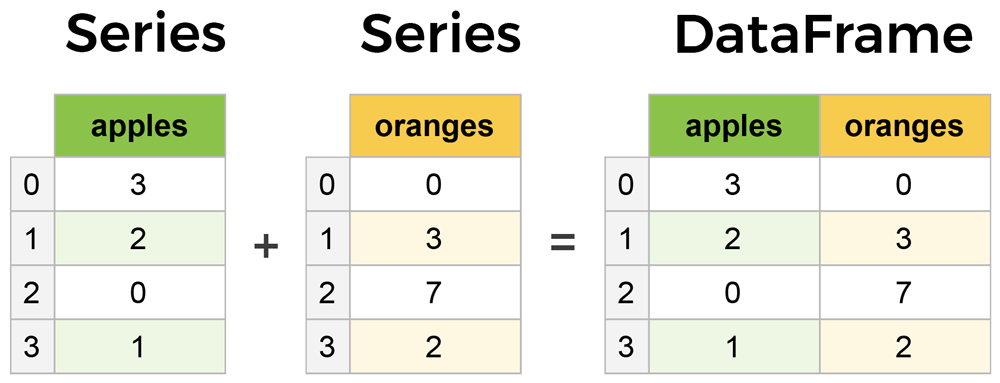
Now that we know various ways of subsetting and slicing our data, we should be able to alter our
data objects.
1. Add Additional Columns
The type of the Born and Died columns is object, meaning they are strings.
print(scientists['Born'].dtype)
object
print(scientists['Died'].dtype)
object
We can convert the strings to a proper datetime type so we can perform common date and time operations
(e.g., take differences between dates or calculate a person’s age). You can provide your own format if you have a date that has a specific format. A list of format variables can be found in the Python datetime module documentation. The format of our date looks like “YYYY-MM-DD,” so we can use the ‘%Y-%m-%d’ format.
# format the 'Born' column as a datetime
born_datetime = pd.to_datetime(scientists['Born'], format='%Y-%m-%d')
print(born_datetime)

# format the 'Died' column as a datetime
died_datetime = pd.to_datetime(scientists['Died'], format='%Y-%m-%d')
If we wanted, we could create a new set of columns that contain the datetime representations of the
object (string) dates. The below example uses python’s multiple assignment syntax:
scientists['born_dt'], scientists['died_dt'] = (born_datetime,
died_datetime)
print(scientists.head())


print(scientists.shape)
(8, 7)
2. Directly Change a Column
We can also assign a new value directly to the existing column. The example in this section shows how to randomize the contents of a column.
First, let’s look at the original Age values.
print(scientists['Age'])

Now let’s shuffle the values.
import random
# set a seed so the randomness is always the same
random.seed(42)
random.shuffle(scientists['Age'])

print(scientists['Age'])

The SettingWithCopyWarning message in the previous code tells us that the proper way of handling
the statement would be to write it using loc, or we can use the built-in sample method to randomly sample the length of the column.
In this example, you need to reset_index since sample picks out only the row index. Thus, if you try to
reassign it or use it again, the “scrambled” values will automatically align to the index and order themselves back to the pre-sample order. The drop=True parameter in reset_index tells Pandas not to insert the index into the dataframe columns, so that only the values are kept.
# the random_state is used to keep the 'randomization' less random
scientists['Age'] = scientists['Age'].\
sample(len(scientists['Age']), random_state=24).\
reset_index(drop=True) # values stay randomized
# we shuffled this column twice
print(scientists['Age'])

Notice that the random.shuffle method seems to work directly on the column. The documentation for
random.shuffle mentions that the sequence will be shuffled “in place,” meaning that it will work directly on the sequence. Contrast this with the previous method, in which we assigned the newly calculated values to a separate variable before we could assign them to the column.
We can recalculate the “real” age using datetime arithmetic.
# subtracting dates gives the number of days
scientists['age_days_dt'] = (scientists['died_dt'] - \
scientists['born_dt'])
print(scientists)

# we can convert the value to just the year
# using the astype method
scientists['age_years_dt'] = scientists['age_days_dt'].\
astype('timedelta64[Y]')
print(scientists)


Many functions and methods in pandas will have an inplace parameter that you can set to True, if you
want to perform the action “in place.” This will directly change the given column without returning anything.
3. Dropping Values
To drop a column, we can either select all the columns we want to by using the column subsetting techniques, or select columns to drop with the drop method on our dataframe.
# all the current columns in our data
print(scientists.columns)
Index(['Name', 'Born', 'Died', 'Age', 'Occupation', 'born_dt',
'died_dt', 'age_days_dt', 'age_years_dt'],
dtype='object')
# drop the shuffled age column
# you provide the axis=1 argument to drop column-wise
scientists_dropped = scientists.drop(['Age'], axis=1)
# columns after dropping our column
print(scientists_dropped.columns)
Index(['Name', 'Born', 'Died', 'Occupation', 'born_dt', 'died_dt',
'age_days_dt', 'age_years_dt'],
dtype='object')
So these were some of the changes we can make to Series and DataFrames. In the next post we'll discuss about Exporting and Importing Data.
0 comments:
Post a Comment