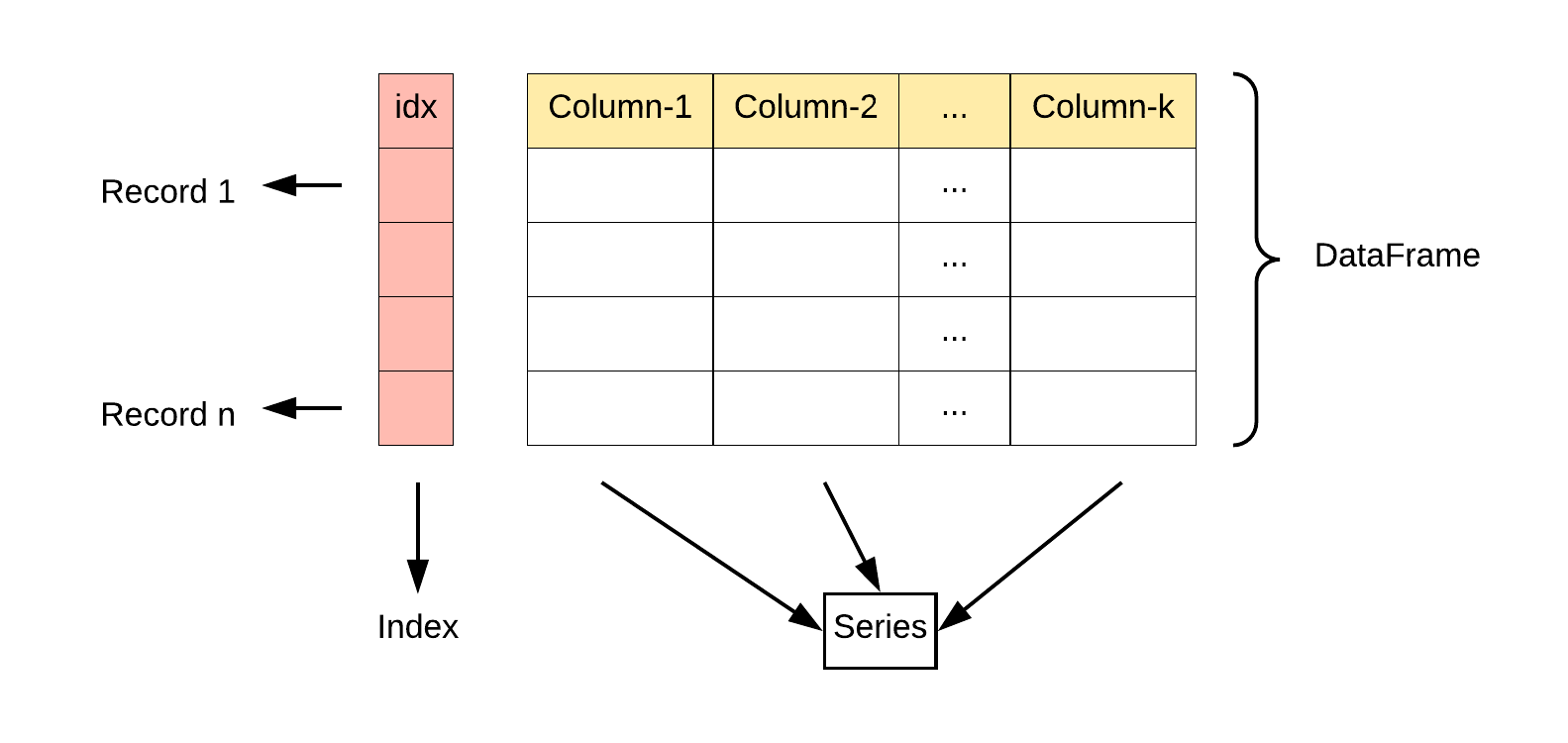
The DataFrame is the most common Pandas object. It can be thought of as Python’s way of storing
spreadsheet-like data. Many of the features of the Series data structure carry over into the DataFrame.
1. Boolean Subsetting: DataFrames
Just as we were able to subset a Series with a boolean vector, so we can subset a DataFrame with a bool.
boolean vectors will subset rows
print(scientists[scientists['Age'] > scientists['Age'].mean()])

Because of how broadcasting works, if we supply a bool vector that is not the same as the number of rows in the dataframe, the maximum number of rows returned would be the length of the bool vector.
# 4 values passed as a bool vector
# 3 rows returned
print(scientists.loc[[True, True, False, True]])

DataFrame Subsetting Methods

Note that ix no longer works after Pandas v0.20.
2. Operations Are Automatically Aligned and Vectorized (Broadcasting)
Pandas supports broadcasting, which comes from the numpy library. In essence, it describes what happens when performing operations between array-like objects, which the Series and DataFrame are. These behaviors depend on the type of object, its length, and any labels associated with the object.
First let’s create a subset of our dataframes.
first_half = scientists[:4]
second_half = scientists[4:]
print(first_half)

print(second_half)

When we perform an action on a dataframe with a scalar, it will try to apply the operation on each cell of the dataframe. In this example, numbers will be multiplied by 2, and strings will be doubled (this is Python’s normal behavior with strings).
# multiply by a scalar
print(scientists * 2)


If your dataframes are all numeric values and you want to “add” the values on a cell-by-cell basis, you can use the add method.
In the next post we'll see how to alter our data objects.
0 comments:
Post a Comment