Pickling
What you want, then, is a way to save your Python data object as itself, so that next time you need it you can simply load it up and get your original object back. Pickling and unpickling let you do that. A Python data object can be "pickled" as itself, which then can be directly loaded ("unpickled") as such at a later point; the process is also known as "object serialization".
Let's see an example:
import pickle
names = ["Vivek","Satya", "Nagaraju"]
skillset = ["Python", "C#", "PHP"]
pickle_file = open('employees.dat','wb')
pickle.dump(names,pickle_file)
pickle.dump(skillset,pickle_file)
pickle_file.close()
The names and skillset are two lists which we have to store.
The pickle_file = open("employees.dat","w") syntax creates a pickle_file object in write binary mode. The pickle.dump() is used to dump and store the lists names and skillset in the employees.dat file. The pickle.dump() requires two arguments, first the data (like list) to pickle and second the file to store it. The pickle_file.close() finally close the file.
Open the employees.dat file to see the content, which in my case is:
€ ]q (X Vivekq X Satyaq X Nagarajuq e.€ ]q (X Pythonq X C#q X PHPq e.
Need for pickling
It is very useful when you want to dump some object while coding in the python shell. So after dumping whenever you restart the python shell you can import the pickled object and de-serialize it. Some other uses are:
Unpickling means retrieving the data from the pickle file. In the previous topic, you learned how to store (list, dictionary) data in the pickle file; now it's time to retrieve the stored data. In order to perform unpickling, we will use pickle.load(). The pickle.load() takes one file object as an argument. Let's see an example:
Given the limitation of the pickle file, you can't access the list randomly, but you can use the dictionary with lists to retrieve the lists randomly.
It's time to unpickle and retrieve the content of the employees1.dat file. See the program below:
import pickle
pickle_file = open("employees1.dat",'rb')
emp_data = pickle.load(pickle_file)
print(emp_data["skillset"])
print(emp_data["names"])
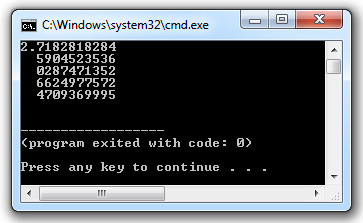
In the preceding program, emp_data is the dictionary and we are accessing the values of the dictionary by keys. The output of the program will be:
['Python', 'C#', 'PHP']
['Vivek', 'Satya', 'Nagaraju']
Here our discussion comes to end. Next post will be on Exception handling which is another important concept. Till we meet next, keep practicing and learning Python as Python is easy to learn!
In order to store complex information such as list and dictionary Python's pickle module is used as text files are limited to storing a series of characters. Once written as a text file, it is a simple text file, meaning next time you read it in you will have parse the text and process it back to your original data structure.
Let's see an example:
import pickle
names = ["Vivek","Satya", "Nagaraju"]
skillset = ["Python", "C#", "PHP"]
pickle_file = open('employees.dat','wb')
pickle.dump(names,pickle_file)
pickle.dump(skillset,pickle_file)
pickle_file.close()
The names and skillset are two lists which we have to store.
The pickle_file = open("employees.dat","w") syntax creates a pickle_file object in write binary mode. The pickle.dump() is used to dump and store the lists names and skillset in the employees.dat file. The pickle.dump() requires two arguments, first the data (like list) to pickle and second the file to store it. The pickle_file.close() finally close the file.
Open the employees.dat file to see the content, which in my case is:
€ ]q (X Vivekq X Satyaq X Nagarajuq e.€ ]q (X Pythonq X C#q X PHPq e.
Need for pickling
It is very useful when you want to dump some object while coding in the python shell. So after dumping whenever you restart the python shell you can import the pickled object and de-serialize it. Some other uses are:
1) saving a program's state data to disk so that it can carry on where it left off when restarted (persistence)
2) sending python data over a TCP connection in a multi-core or distributed system (marshalling)
3) storing python objects in a database
4) converting an arbitrary python object to a string so that it can be used as a dictionary key (e.g. for caching & memoization).
Unpickling
Unpickling means retrieving the data from the pickle file. In the previous topic, you learned how to store (list, dictionary) data in the pickle file; now it's time to retrieve the stored data. In order to perform unpickling, we will use pickle.load(). The pickle.load() takes one file object as an argument. Let's see an example:
import pickle
pickle_file = open("employees.dat",'rb')
names_list = pickle.load(pickle_file)
skillset_list =pickle.load(pickle_file)
print (names_list ,"and", skillset_list)
pickle_file = open("employees.dat",'rb')
names_list = pickle.load(pickle_file)
skillset_list =pickle.load(pickle_file)
print (names_list ,"and", skillset_list)
The pickle_file = open("employees.dat",'rb') syntax creates a file object in read mode. The names_list = pickle.load(pickle_file) syntax reads the first pickled object in the file and unpickles it. Similarly, skillset_list =pickle.load(pickle_file) reads the second pickled object in the file and unpickles it.
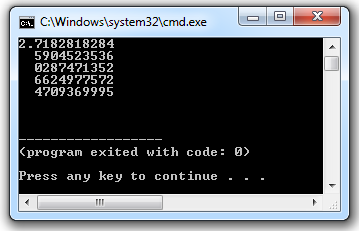
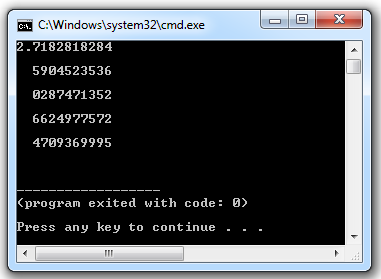
The output of this program is:
['Vivek', 'Satya', 'Nagaraju'] and ['Python', 'C#', 'PHP']
In pickle, you can not access the data randomly. Pickle stores and retrieves the list
sequentially. The data you dump in the pickle file first, would be retrieved first. This is the limitation of the pickle file.
sequentially. The data you dump in the pickle file first, would be retrieved first. This is the limitation of the pickle file.
Given the limitation of the pickle file, you can't access the list randomly, but you can use the dictionary with lists to retrieve the lists randomly.
Let's see this through an example:
import pickle
pickle_file = open('employees1.dat','wb')
emp_dict = {
'names' : ["Vivek","Satya", "Nagaraju"],
'skillset' : ["Python", "C#", "PHP"]
}
pickle.dump(emp_dict,pickle_file)
pickle_file.close()
pickle_file = open('employees1.dat','wb')
emp_dict = {
'names' : ["Vivek","Satya", "Nagaraju"],
'skillset' : ["Python", "C#", "PHP"]
}
pickle.dump(emp_dict,pickle_file)
pickle_file.close()
Through this program we have dumped a dictionary referred by name emp_dict . When we run the preceding program and check the directory. A file named employees1.dat must be created. If I open this file its content is:
€ }q (X namesq ]q (X Vivekq X Satyaq X Nagarajuq eX skillsetq ]q (X Pythonq X C#q X PHPqeu.
import pickle
pickle_file = open("employees1.dat",'rb')
emp_data = pickle.load(pickle_file)
print(emp_data["skillset"])
print(emp_data["names"])
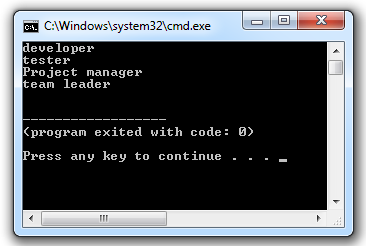
In the preceding program, emp_data is the dictionary and we are accessing the values of the dictionary by keys. The output of the program will be:
['Python', 'C#', 'PHP']
['Vivek', 'Satya', 'Nagaraju']
Here our discussion comes to end. Next post will be on Exception handling which is another important concept. Till we meet next, keep practicing and learning Python as Python is easy to learn!