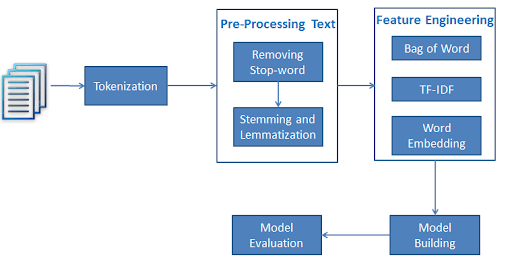
Tokenization
It may be defined as the process of breaking the given text i.e. the character sequence into smaller units called tokens. The tokens may be the words, numbers or punctuation marks. It is also called word segmentation. Following is a simple example of tokenization:
Output:
Mango
BananaPineapple
and
Apple
all
are
Fruits
The process of breaking the given text can be done with the help of locating the word boundaries. The ending of a word and the beginning of a new word are called word boundaries. The writing system and the typographical structure of the words influence the boundaries.
In the Python NLTK module, we have different packages related to tokenization which we can use to divide the text into tokens as per our requirements. Some of the packages are as follows:
As the name suggest, this package will divide the input text into sentences. We can import this package with the help of the following Python code:
from nltk.tokenize import sent_tokenize
word_tokenize package
This package divides the input text into words. We can import this package with the help of the following Python code:
from nltk.tokenize import word_tokenize
WordPunctTokenizer package
This package divides the input text into words as well as the punctuation marks. We can import this package with the help of the following Python code:
from nltk.tokenize import WordPuncttokenizer
Stemming
While working with words, we come across a lot of variations due to grammatical reasons. The concept of variations here means that we have to deal with different forms of the same words like democracy, democratic, and democratization. It is very necessary for machines to understand that these different words have the same base form. In this way, it would be useful to extract the base forms of the words while we are analyzing the text.
We can achieve this by stemming. In this way, we can say that stemming is the heuristic process of extracting the base forms of the words by chopping off the ends of words.
In the Python NLTK module, we have different packages related to stemming. These packages can be used to get the base forms of word. These packages use algorithms. Some of the packages are as follows:
PorterStemmer package
This Python package uses the Porter’s algorithm to extract the base form. We can import this package with the help of the following Python code:
from nltk.stem.porter import PorterStemmer
For example, if we will give the word ‘writing’ as the input to this stemmer them we will get the word ‘write’ after stemming.
LancasterStemmer package
This Python package will use the Lancaster’s algorithm to extract the base form. We can import this package with the help of the following Python code:
from nltk.stem.lancaster import LancasterStemmer
For example, if we will give the word ‘writing’ as the input to this stemmer them we will get the word ‘writ’ after stemming.
SnowballStemmer package
This Python package will use the snowball’s algorithm to extract the base form. We can import this package with the help of the following Python code:
from nltk.stem.snowball import SnowballStemmer
For example, if we will give the word ‘writing’ as the input to this stemmer then we will get the word ‘write’ after stemming.
All of these algorithms have different level of strictness. If we compare these three stemmers then the Porter stemmers is the least strict and Lancaster is the strictest. Snowball stemmer is good to use in terms of speed as well as strictness.
Lemmatization
We can also extract the base form of words by lemmatization. It basically does this task with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only. This kind of base form of any word is called lemma.
The main difference between stemming and lemmatization is the use of vocabulary and morphological analysis of the words. Another difference is that stemming most commonly collapses derivationally related words whereas lemmatization commonly only collapses the different inflectional forms of a lemma. For example, if we provide the word saw as the input word then stemming might return the word ‘s’ but lemmatization would attempt to return the word either see or saw depending on whether the use of the token was a verb or a noun.
In the Python NLTK module, we have the following package related to lemmatization process which we can use to get the base forms of word:
WordNetLemmatizer package
This Python package will extract the base form of the word depending upon whether it is used as a noun or as a verb. We can import this package with the help of the following Python code:
from nltk.stem import WordNetLemmatizer
Here I am ending this post in which we tried to understand what is tokenization, stemming, and lemmatization. Next post will be on chunking.
0 comments:
Post a Comment