One important requirement we already know for machine learning algorithms is that data in a certain format is necessary . Another important requirement is that the data must be labelled properly before sending it as the input of machine learning algorithms. For example, if we talk about classification, there are lot of labels on the data. Those labels are in the form of words, numbers, etc. Functions related to machine learning in sklearn expect that the data must have number labels. Hence, if the data is in other form then it must be converted to numbers. This process of transforming the word labels into numerical form is called label encoding.
Unlabeled data mainly consists of the samples of natural or human-created object that can easily be obtained from the world. They include, audio, video, photos, news articles, etc.
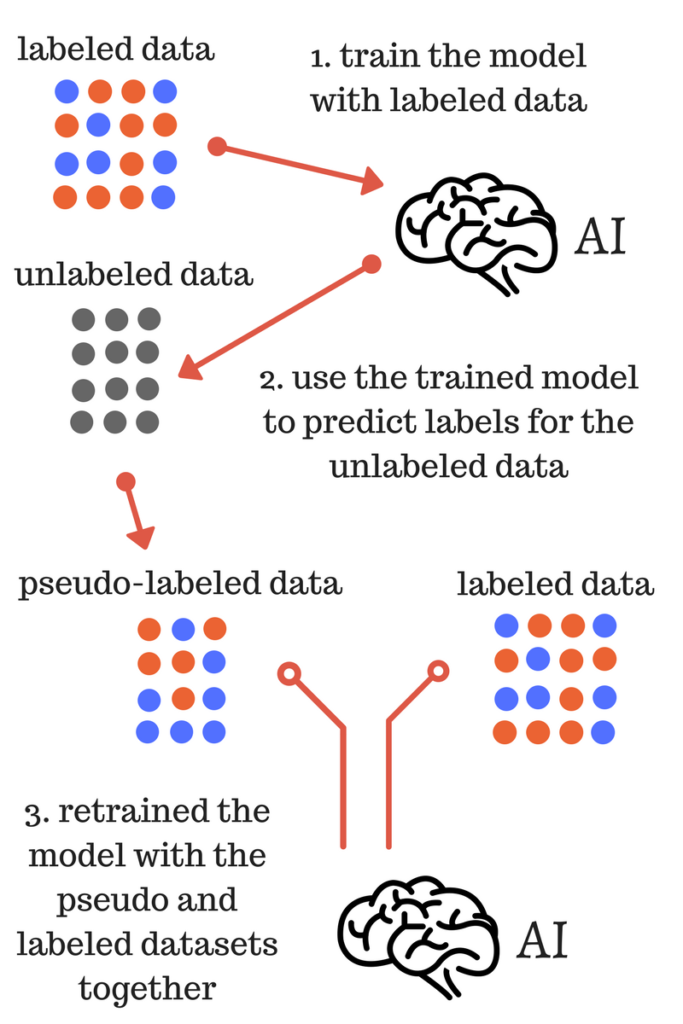
On the other hand, labeled data takes a set of unlabeled data and augments each piece of that unlabeled data with some tag or label or class that is meaningful. For example, if we have a photo then the label can be put based on the content of the photo, i.e., it is photo of a boy or girl or animal or anything else. Labeling the data needs human expertise or judgment about a given piece of unlabeled data.
There are many scenarios where unlabeled data is plentiful and easily obtained but labeled data often requires a human/expert to annotate. Semi-supervised learning attempts to combine labeled and unlabeled data to build better models.
Follow these steps for encoding the data labels in Python:
Step1: Importing the useful packages
If we are using Python then this would be first step for converting the data into certain format, i.e., preprocessing. It can be done as follows:
import numpy as np
from sklearn import preprocessing
from sklearn import preprocessing
Step 2: Defining sample labels
After importing the packages, we need to define some sample labels so that we can create and train the label encoder. We will now define the following sample labels:
# Sample input labels
input_labels = ['red','black','red','green','black','yellow','white']
input_labels = ['red','black','red','green','black','yellow','white']
Step 3: Creating & training of label encoder object
In this step, we need to create the label encoder and train it. The following Python code will help in doing this:
# Creating the label encoder
encoder = preprocessing.LabelEncoder()
encoder.fit(input_labels)
encoder = preprocessing.LabelEncoder()
encoder.fit(input_labels)
Following would be the output after running the above Python code:
LabelEncoder()
Step4: Checking the performance by encoding random ordered list
This step can be used to check the performance by encoding the random ordered list. Following Python code can be written to do the same:
# encoding a set of labels
test_labels = ['green','red','black']
encoded_values = encoder.transform(test_labels)
print("\nLabels =", test_labels)
test_labels = ['green','red','black']
encoded_values = encoder.transform(test_labels)
print("\nLabels =", test_labels)
The labels would get printed as follows:
Labels = ['green', 'red', 'black']
Now, we can get the list of encoded values i.e. word labels converted to numbers as follows:
print("Encoded values =", list(encoded_values))
The encoded values would get printed as follows:
Encoded values = [1, 2, 0]
Step 5: Checking the performance by decoding a random set of numbers:
This step can be used to check the performance by decoding the random set of numbers. Following Python code can be written to do the same:
# decoding a set of values
encoded_values = [3,0,4,1]
decoded_list = encoder.inverse_transform(encoded_values)
print("\nEncoded values =", encoded_values)
encoded_values = [3,0,4,1]
decoded_list = encoder.inverse_transform(encoded_values)
print("\nEncoded values =", encoded_values)
Now, Encoded values would get printed as follows:
Encoded values = [3, 0, 4, 1]
print("\nDecoded labels =", list(decoded_list))
Now, decoded values would get printed as follows:
Decoded labels = ['white', 'black', 'yellow', 'green']
0 comments:
Post a Comment