Let's have an introductory overview of the world of deep learning and the artificial neural networks on which its techniques are based. Furthermore, among the new Python frameworks for deep learning, we will use TensorFlow, which is proving to be an excellent tool for research and development of deep learning analysis techniques. With this library we will see how to develop different models of neural networks that are the basis of deep learning.
Artificial intelligence
AI can be defined as
"Automatic processing on a computer capable of performing operations that would seem to be exclusively relevant to human intelligence."
Hence the concept of artificial intelligence is a variable concept that varies with the progress of the machines themselves and with the concept of “exclusive human relevance”. In the last few years, the concept of artificial intelligence has focused on visual and auditory recognition operations, which until recently were thought of as “exclusive human relevance”. These operations include:
• Image recognition
• Object detection
• Object segmentation
• Language translation
• Natural language understanding
• Speech recognition
Machine learning (ML), with all its techniques and algorithms, is a large branch of artificial intelligence. In fact, you refer to it, while remaining within the ambit of artificial intelligence when you use systems that are able to learn (learning systems) to solve various problems that shortly before had been “considered exclusive to humans”.
Within the machine learning techniques, a further subclass can be defined, called deep learning. We already know that machine learning uses systems that can learn, and this can be done through features inside the system (often parameters of a fixed model) that are modified in response to input data intended for learning (training set).
Deep learning techniques take a step forward. In fact, deep learning systems are structured so as not to have these intrinsic characteristics in the model, but these characteristics are extracted and detected by the system automatically as a result of learning itself. Among these systems that can do this, we refer in particular to artificial neural networks.
The figure below shows the relationship between Artificial Intelligence, Machine
Learning, and Deep Learning:
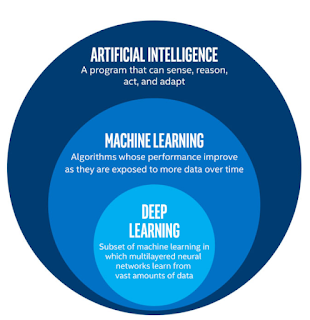
Deep learning
Deep learning has become popular only in the last few years precisely to solve problems of visual and auditory recognition.
In the context of deep learning, a lot of calculation techniques and algorithms have been developed in recent years, making the most of the potential of the Python language. Thought the theory behind deep learning actually dates back many years, it's only in recent years the neural networks, with the related deep learning techniques that use them, have proved useful to solve many problems of
artificial intelligence.
At the application level, deep learning requires very complex mathematical operations that require millions or even billions of parameters. The CPUs of the 90s, even if powerful, were not able to perform these kinds of operations in efficient times. Even today the calculation with the CPUs, although considerably improved, requires long processing times. This inefficiency is due to the particular architecture of the CPUs, which have been designed to efficiently perform mathematical operations that are not those required by neural networks.
Then Graphics Processing Unit (GPU) were designed to manage more and more efficient vector calculations, such as multiplications between matrices, which is necessary for 3D reality simulations and rendering.
Because of GPU many deep learning techniques have been realized. In fact, to realize the neural networks and their learning, the tensors (multidimensional matrices) are used, carrying out many mathematical operations. It is precisely this kind of work that GPUs are able to do more efficiently. Now the processing speed of deep learning is increased by several orders of magnitude (days instead of months).
Another very important factor affecting the development of deep learning is the huge amount of data that can be accessed. In fact, the data are the fundamental ingredient for the functioning of neural networks, both for the learning phase and for their verification phase. A few years ago only a few organizations were providing data for analysis, today, with the technology such as the IoT (Internet of Things), many sensors and devices acquire data and make them available on networks. Even social networks and search engines (like Facebook, Google, and so on) can collect huge amounts of data,
analyzing in real time millions of users connected to their services (called Big Data).
Thus now a days, a lot of data related to the problems we want to solve with the deep learning techniques, are easily available not only for a fee, but also in free form (open data source).
Python programming language also contributed to the great success and diffusion of deep learning
techniques. In the past, planning neural network systems was very complex. The only language able to carry out this task was C ++, a very complex language, difficult to use and known only to a few specialists. Moreover, in order to work with the GPU (necessary for this type of calculation), it was necessary to know CUDA (Compute Unified Device Architecture), the hardware development architecture of NVIDIA graphics cards with all their technical specifications.
Now because of Python, the programming of neural networks and deep learning techniques has become high level. In fact, programmers no longer have to think about the architecture and the technical specifications of the graphics card (GPU), but can focus exclusively on the part related to deep learning. Moreover the characteristics of the Python language enable programmers to develop simple and intuitive code.
Over the past two years many developer organizations and communities have been developing Python frameworks that are greatly simplifying the calculation and application of deep learning techniques. Among these frameworks available today for free, it is worth mentioning some that
are gaining some success.
• TensorFlow is an open source library for numerical calculation that bases its use on data flow graphs. These are graphs where the nodes represent the mathematical operations and the edges represent tensors (multidimensional data arrays). Its architecture is very flexible and can distribute the calculations both on multiple CPUs and on multiple GPUs.
• Caffe2 is a framework developed to provide an easy and simple way to work on deep learning. It allows you to test model and algorithm calculations using the power of GPUs in the cloud.
• PyTorch is a scientific framework completely based on the use of GPUs. It works in a highly efficient way and was recently developed and is still not well consolidated. It is still proving a powerful tool for scientific research.
• Theano is the most used Python library in the scientific field for the development, definition, and evaluation of mathematical expressions and physical models. Unfortunately, the development team
announced that new versions will no longer be released. However, it remains a reference framework as number of programs were developed with this library, both in literature and on the web.
Here I am ending today's discussion wherein we covered the basics of deep learning. In the next post I'll focus on the artificial neural networks on which its techniques are based. So till we meet again keep learning and practicing Python as Python is easy to learn!
Artificial intelligence
AI can be defined as
"Automatic processing on a computer capable of performing operations that would seem to be exclusively relevant to human intelligence."
Hence the concept of artificial intelligence is a variable concept that varies with the progress of the machines themselves and with the concept of “exclusive human relevance”. In the last few years, the concept of artificial intelligence has focused on visual and auditory recognition operations, which until recently were thought of as “exclusive human relevance”. These operations include:
• Image recognition
• Object detection
• Object segmentation
• Language translation
• Natural language understanding
• Speech recognition
Machine learning (ML), with all its techniques and algorithms, is a large branch of artificial intelligence. In fact, you refer to it, while remaining within the ambit of artificial intelligence when you use systems that are able to learn (learning systems) to solve various problems that shortly before had been “considered exclusive to humans”.
Within the machine learning techniques, a further subclass can be defined, called deep learning. We already know that machine learning uses systems that can learn, and this can be done through features inside the system (often parameters of a fixed model) that are modified in response to input data intended for learning (training set).
Deep learning techniques take a step forward. In fact, deep learning systems are structured so as not to have these intrinsic characteristics in the model, but these characteristics are extracted and detected by the system automatically as a result of learning itself. Among these systems that can do this, we refer in particular to artificial neural networks.
The figure below shows the relationship between Artificial Intelligence, Machine
Learning, and Deep Learning:

Deep learning
Deep learning has become popular only in the last few years precisely to solve problems of visual and auditory recognition.
In the context of deep learning, a lot of calculation techniques and algorithms have been developed in recent years, making the most of the potential of the Python language. Thought the theory behind deep learning actually dates back many years, it's only in recent years the neural networks, with the related deep learning techniques that use them, have proved useful to solve many problems of
artificial intelligence.
At the application level, deep learning requires very complex mathematical operations that require millions or even billions of parameters. The CPUs of the 90s, even if powerful, were not able to perform these kinds of operations in efficient times. Even today the calculation with the CPUs, although considerably improved, requires long processing times. This inefficiency is due to the particular architecture of the CPUs, which have been designed to efficiently perform mathematical operations that are not those required by neural networks.
Then Graphics Processing Unit (GPU) were designed to manage more and more efficient vector calculations, such as multiplications between matrices, which is necessary for 3D reality simulations and rendering.
Because of GPU many deep learning techniques have been realized. In fact, to realize the neural networks and their learning, the tensors (multidimensional matrices) are used, carrying out many mathematical operations. It is precisely this kind of work that GPUs are able to do more efficiently. Now the processing speed of deep learning is increased by several orders of magnitude (days instead of months).
Another very important factor affecting the development of deep learning is the huge amount of data that can be accessed. In fact, the data are the fundamental ingredient for the functioning of neural networks, both for the learning phase and for their verification phase. A few years ago only a few organizations were providing data for analysis, today, with the technology such as the IoT (Internet of Things), many sensors and devices acquire data and make them available on networks. Even social networks and search engines (like Facebook, Google, and so on) can collect huge amounts of data,
analyzing in real time millions of users connected to their services (called Big Data).
Thus now a days, a lot of data related to the problems we want to solve with the deep learning techniques, are easily available not only for a fee, but also in free form (open data source).
Python programming language also contributed to the great success and diffusion of deep learning
techniques. In the past, planning neural network systems was very complex. The only language able to carry out this task was C ++, a very complex language, difficult to use and known only to a few specialists. Moreover, in order to work with the GPU (necessary for this type of calculation), it was necessary to know CUDA (Compute Unified Device Architecture), the hardware development architecture of NVIDIA graphics cards with all their technical specifications.
Now because of Python, the programming of neural networks and deep learning techniques has become high level. In fact, programmers no longer have to think about the architecture and the technical specifications of the graphics card (GPU), but can focus exclusively on the part related to deep learning. Moreover the characteristics of the Python language enable programmers to develop simple and intuitive code.
Over the past two years many developer organizations and communities have been developing Python frameworks that are greatly simplifying the calculation and application of deep learning techniques. Among these frameworks available today for free, it is worth mentioning some that
are gaining some success.
• TensorFlow is an open source library for numerical calculation that bases its use on data flow graphs. These are graphs where the nodes represent the mathematical operations and the edges represent tensors (multidimensional data arrays). Its architecture is very flexible and can distribute the calculations both on multiple CPUs and on multiple GPUs.
• Caffe2 is a framework developed to provide an easy and simple way to work on deep learning. It allows you to test model and algorithm calculations using the power of GPUs in the cloud.
• PyTorch is a scientific framework completely based on the use of GPUs. It works in a highly efficient way and was recently developed and is still not well consolidated. It is still proving a powerful tool for scientific research.
• Theano is the most used Python library in the scientific field for the development, definition, and evaluation of mathematical expressions and physical models. Unfortunately, the development team
announced that new versions will no longer be released. However, it remains a reference framework as number of programs were developed with this library, both in literature and on the web.
Here I am ending today's discussion wherein we covered the basics of deep learning. In the next post I'll focus on the artificial neural networks on which its techniques are based. So till we meet again keep learning and practicing Python as Python is easy to learn!
0 comments:
Post a Comment