TensorFlow is one of the several frameworks in Python that allow you to develop projects for deep learning. This library was developed by the Google Brain Team, a group of Machine Learning Intelligence, a research organization headed by Google.
TensorFlow is already a consolidated deep learning framework, rich in documentation, tutorials, and projects available on the Internet. In addition to the main package, there are many other libraries that have been released over time, including:
• TensorBoard—A kit that allows the visualization of internal graphs to TensorFlow
• TensorFlow Fold—Produces beautiful dynamic calculation charts
• TensorFlow Transform—Created and managed input data pipelines
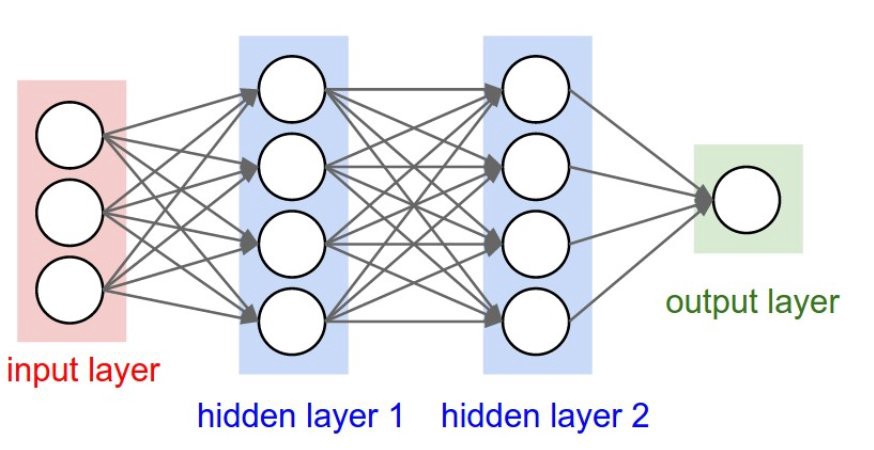
TensorFlow is based entirely on the structuring and use of graphs and on the flow of data through it, exploiting them in such a way as to make mathematical calculations. The graph created internally to the TensorFlow runtime system is called Data Flow Graph and it is structured in runtime according to the mathematical model that is the basis of the calculation we want to perform. In fact, Tensor Flow allows us to define any mathematical model through a series of instructions implemented in the code.
TensorFlow will take care of translating that model into the Data Flow Graph internally. So when we go to model our deep learning neural network, it will be translated into a Data Flow Graph. Given the great similarity between the structure of neural networks and the mathematical representation of graphs, it is easy to understand why this library is excellent for developing deep learning projects.
TensorFlow is not limited to deep learning and can be used to represent artificial neural networks. Many other methods of calculation and analysis can be implemented with this library, since any physical system can be represented with a mathematical model. In fact, this library can also be used to implement other machine learning techniques, and for the study of complex physical systems through the calculation of partial differentials, etc.
The nodes of the Data Flow Graph represent mathematical operations, while the edges of the graph represent tensors (multidimensional data arrays). The name TensorFlow derives from the fact that these tensors represent the flow of data through graphs, which can be used to model artificial neural networks.
Here I am ending today's discussion wherein we covered the basics of TensorFlow framework. In the next post I'll focus on Programming with TensorFlow . So till we meet again keep learning and practicing Python as Python is easy to learn!
TensorFlow is already a consolidated deep learning framework, rich in documentation, tutorials, and projects available on the Internet. In addition to the main package, there are many other libraries that have been released over time, including:
• TensorBoard—A kit that allows the visualization of internal graphs to TensorFlow
• TensorFlow Fold—Produces beautiful dynamic calculation charts
• TensorFlow Transform—Created and managed input data pipelines
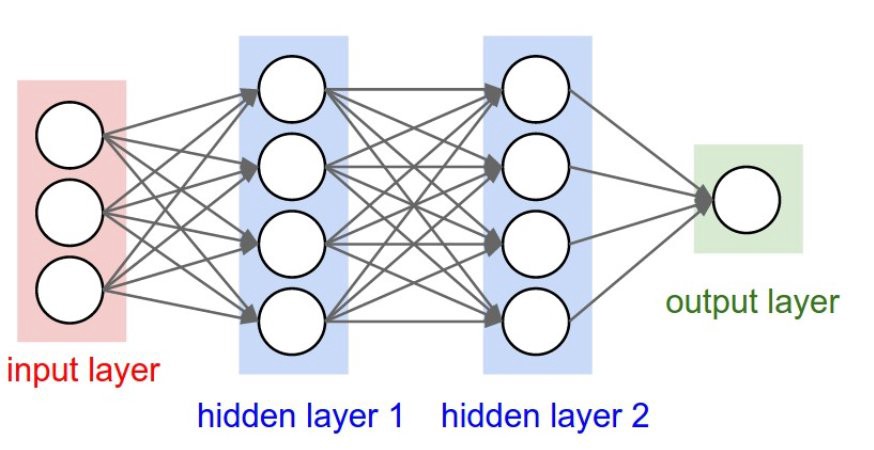
TensorFlow is based entirely on the structuring and use of graphs and on the flow of data through it, exploiting them in such a way as to make mathematical calculations. The graph created internally to the TensorFlow runtime system is called Data Flow Graph and it is structured in runtime according to the mathematical model that is the basis of the calculation we want to perform. In fact, Tensor Flow allows us to define any mathematical model through a series of instructions implemented in the code.
TensorFlow will take care of translating that model into the Data Flow Graph internally. So when we go to model our deep learning neural network, it will be translated into a Data Flow Graph. Given the great similarity between the structure of neural networks and the mathematical representation of graphs, it is easy to understand why this library is excellent for developing deep learning projects.
TensorFlow is not limited to deep learning and can be used to represent artificial neural networks. Many other methods of calculation and analysis can be implemented with this library, since any physical system can be represented with a mathematical model. In fact, this library can also be used to implement other machine learning techniques, and for the study of complex physical systems through the calculation of partial differentials, etc.
The nodes of the Data Flow Graph represent mathematical operations, while the edges of the graph represent tensors (multidimensional data arrays). The name TensorFlow derives from the fact that these tensors represent the flow of data through graphs, which can be used to model artificial neural networks.
Here I am ending today's discussion wherein we covered the basics of TensorFlow framework. In the next post I'll focus on Programming with TensorFlow . So till we meet again keep learning and practicing Python as Python is easy to learn!