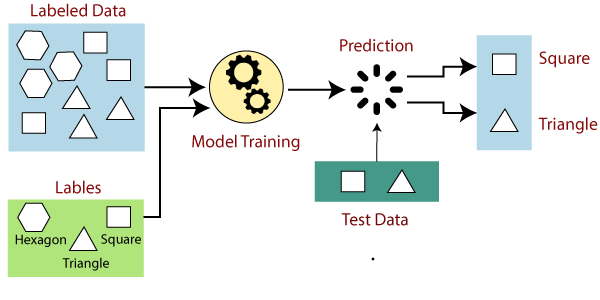
Instead of manually writing down exact rules to do the classification, the point in supervised machine learning is to take a number of examples, label each one by the correct label, and use them to “train” an AI method to automatically recognize the correct label for the training examples as well as (at least hopefully) any other images. This of course requires that the correct labels are provided, which is why we talk about supervised learning. The user who provides the correct labels is a supervisor who guides the learning algorithm towards correct answers so that eventually, the algorithm can independently produce them.
In addition to learning how to predict the correct label in a classification problem, supervised learning can also be used in situations where the predicted outcome is a number. Examples include predicting the number of people who will click a Google ad based on the ad content and data about the user’s prior online behavior, predicting the number of traffic accidents based on road conditions and speed limit, or predicting the selling price of real estate based on its location, size, and condition. These problems are called regression. You probably recognize the term linear regression, which is a classical, still very popular technique for regression.
Example
Suppose we have a data set consisting of apartment sales data. For each purchase, we would obviously have the price that was paid, together with the size of the apartment in square meters (or square feet, if you like), and the number of bedrooms, the year of construction, the condition (on a scale from “disaster“ to “spick and span”). We could then use machine learning to train a regression model that predicts the selling price based on these features.
There are a couple potential mistakes that I'd like to make you aware of. They are related to the fact that unless you are careful with the way you apply machine learning methods, you could become too confident about the accuracy of your predictions, and be heavily disappointed when the accuracy turns out to be worse than expected.
The first thing to keep in mind in order to avoid big mistakes, is to split your data set into two parts: the training data and the test data. We first train the algorithm using only the training data. This gives us a model or a rule that predicts the output based on the input variables.
To assess how well we can actually predict the outputs, we can't count on the training data. While a model may be a very good predictor in the training data, it is no proof that it can generalize to any other data. This is where the test data comes in handy: we can apply the trained model to predict the outputs for the test data and compare the predictions to the actual outputs (for example, future apartment sale prices).
Too fit to be true! Overfitting alert
It is very important to keep in mind that the accuracy of a predictor learned by machine learning can be quite different in the training data and in separate test data. This is the so-called overfitting phenomenon, and a lot of machine learning research is focused on avoiding it one way or another. Intuitively, overfitting means trying to be too smart. When predicting the success of a new song by a known artist, you can look at the track record of the artist's earlier songs, and come up with a rule like “if the song is about love, and includes a catchy chorus, it will be top-20”. However, maybe there are two love songs with catchy choruses that didn't make the top-20, so you decide to continue the rule “...except if Sweden or yoga are mentioned” to improve your rule. This could make your rule fit the past data perfectly, but it could in fact make it work worse on future test data.
Machine learning methods are especially prone to overfitting because they can try a huge number of different “rules” until one that fits the training data perfectly is found. Especially methods that are very flexible and can adapt to almost any pattern in the data can overfit unless the amount of data is enormous. For example, compared to quite restricted linear models obtained by linear regression, neural networks can require massive amounts of data before they produce reliable prediction.
Learning to avoid overfitting and choose a model that is not too restricted, nor too flexible, is one of the most essential skills of a data scientist.
In the next post we'll discuss about unsupervised learning.
0 comments:
Post a Comment