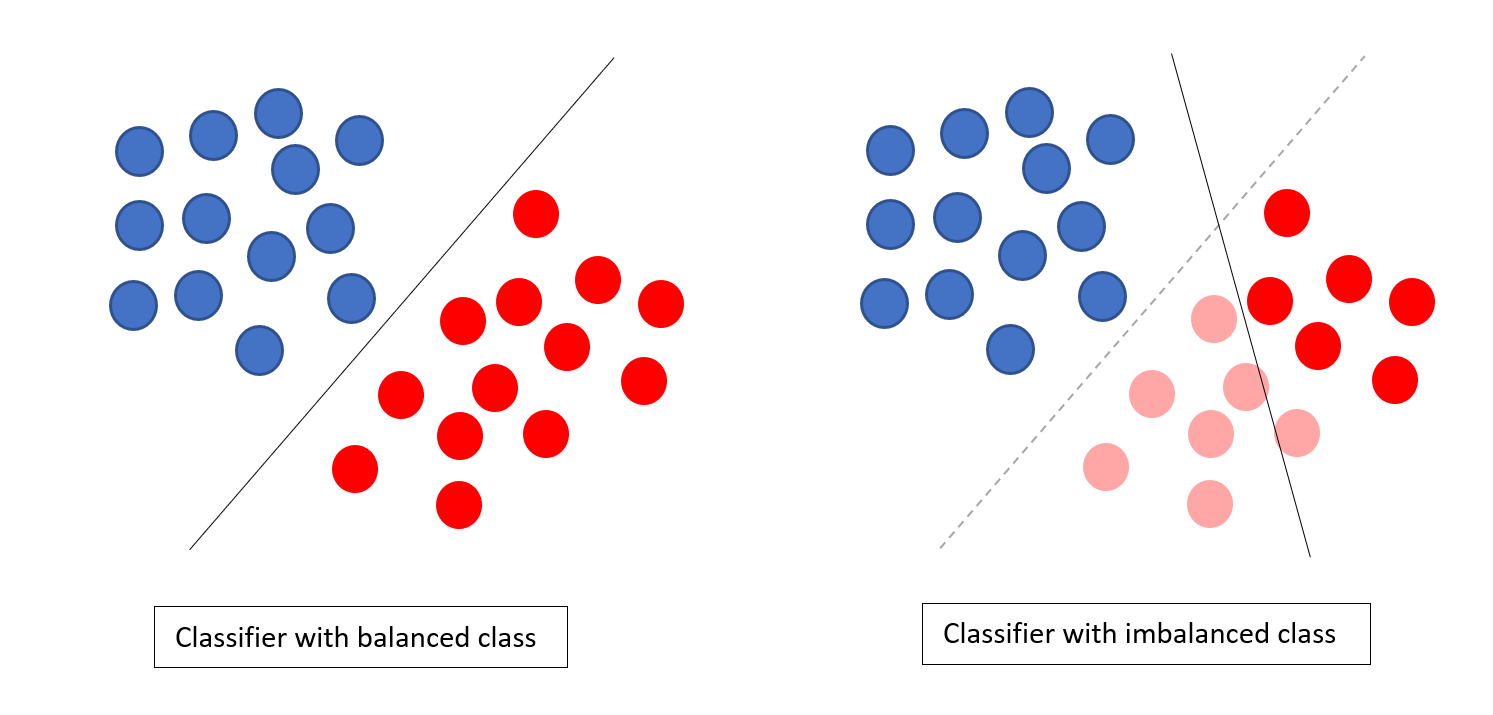
Example of imbalanced classes
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%
Solution
Balancing the classes’ acts as a solution to imbalanced classes. The main objective of balancing the classes is to either increase the frequency of the minority class or decrease the frequency of the majority class. Following are the approaches to solve the issue of imbalances classes:
Re-Sampling
Re-sampling is a series of methods used to reconstruct the sample data sets - both training sets and testing sets. Re-sampling is done to improve the accuracy of model. Following are some re-sampling techniques:
Random Under-Sampling: This technique aims to balance class distribution by randomly eliminating majority class examples. This is done until the majority and minority class instances are balanced out.
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%
In this case, we are taking 10% samples without replacement from non-fraud instances and then combine them with the fraud instances:
Non-fraudulent observations after random under sampling = 10% of 4950 = 495
Total observations after combining them with fraudulent observations = 50+495 = 545
Total observations after combining them with fraudulent observations = 50+495 = 545
Hence now, the event rate for new dataset after under sampling = 9%
The main advantage of this technique is that it can reduce run time and improve storage. But on the other side, it can discard useful information while reducing the number of training data samples.
Random Over-Sampling: This technique aims to balance class distribution by increasing the number of instances in the minority class by replicating them.
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%
In case we are replicating 50 fraudulent observations 30 times then fraudulent observations after replicating the minority class observations would be 1500. And then total observations in the new data after oversampling would be 4950+1500 = 6450. Hence the event rate for the new data set would be
1500/6450 = 23%.
The main advantage of this method is that there would be no loss of useful information. But on the other hand, it has the increased chances of over-fitting because it replicates the minority class events.
0 comments:
Post a Comment